

LLO, or Low-Level Optimization, supports AI crawlers and answer engines by turning a website’s technical setup into a machine-readable environment that focuses on fast, direct access to data instead of heavy client-side code. By making sure key content comes in the first HTML response instead of being loaded later with large JavaScript bundles, LLO helps AI bots quickly read, process, and quote a brand’s information.
This technical bridge closes the “visibility gap” where advanced generative models may miss dynamic content, so your data can act as the trusted “source of truth” for AI-generated answers.
In today’s search landscape, LLO – AI technical Optimisation has become a must-have for brands that want to keep their authority. As answer engines like Perplexity and ChatGPT-Search increasingly combine information into direct responses instead of just listing links, a site’s technical setup now controls its “citation readiness.”
Without a strong LLO framework, even excellent content can sit behind technical walls, unseen by the algorithms that drive discovery and demand.
What Is LLO and Why Does AI Discovery Matter?
How Do AI Crawlers and Answer Engines Differ from Traditional Search Bots?
Traditional search bots, such as Googlebot or Bingbot, were built mainly to crawl pages and build a searchable index of links. Their job is to match keywords to pages and rank those pages by authority and relevance. While Google now renders JavaScript, its main output is still a Search Engine Results Page (SERP).
AI crawlers like GPTBot (OpenAI) and ClaudeBot (Anthropic) work more like scraping tools that pull specific text and data to train Large Language Models (LLMs) or to power real-time answers through Retrieval-Augmented Generation (RAG).
AI crawlers usually work in two modes: training and retrieval. Training bots run wide crawls across sites to build the AI’s long-term memory. Retrieval bots load specific URLs on demand to answer user questions with fresh information.
Traditional bots tend to follow a predictable schedule. By contrast, AI retrieval bots are triggered by user prompts and can hit a site hundreds of times a day on trending topics, placing much higher pressure on server speed and uptime.
Why Is Optimizing for AI Models and Answer Engines Important Now?
We are now in an “AI-first” search era, where millions of people get answers directly inside chat-style tools without ever clicking through to a website. If your brand is not cited in these answers, it is effectively invisible in the AI-driven attention economy.
Visibility is no longer just about ranking at the top; it is about being the trusted “grounding” source an AI relies on to form its natural language response. This change makes AI discovery a key factor for digital marketing survival.

User habits around research are changing fast. Studies show younger users, especially Gen Z, are moving to AI assistants and social discovery instead of classic search engines. These models favor clarity, accuracy, and machine-readable content. Brands that adapt early gain a strong early-mover advantage. Becoming an AI’s “default source” now builds a reinforcing loop of authority that will be very hard for latecomers to replace later.
What Blocks AI Crawlers and How LLO Solves It
Common Technical Barriers to AI Crawler Access
The biggest blocker to AI discovery is heavy reliance on client-side JavaScript. Recent studies show that around 69% of major AI crawlers cannot run JavaScript. Googlebot uses an up-to-date Chromium engine to render dynamic content, but bots like GPTBot and PerplexityBot often see only the raw HTML served by the server.
If your product names, prices, or reviews load via React or Vue after the first page load, these bots do not see them. LLO fixes this by focusing on Server-Side Rendering (SSR) or pre-rendering, so the “response HTML” already contains all key information. For SaaS and tech firms aiming for a worldwide presence, overcoming these technical barriers is a priority, and https://non.agency/en/ provides the deep technical SEO expertise needed to ensure your infrastructure is fully accessible to AI bots across every target market.
Other strong blockers include slow server response and many 404 errors. AI systems often run with strict timeouts, usually between 1 and 5 seconds. If a page is weighed down with large scripts or massive images, an AI crawler may give up before capturing the content.
LLO reduces HTML size and moves the most important information to the top of the document, so even if a bot has a short “time budget,” it collects the main facts first.
How LLO Prevents Indexation of Problematic or Sensitive Content
AI bots are very “data hungry”; they do more than scan headings. They can read code comments, metadata, and JSON that classic search bots may ignore. This can be risky if a brand leaves private details or embarrassing developer notes in the source code.
LLO applies a strict clean-up process so the HTML that reaches crawlers is clean and holds only data meant for public use. This reduces the risk that sensitive internal information ends up inside an LLM’s training data forever.

LLO setups also use robots.txt and the new llms.txt standard to mark clear “off limits” areas for AI. Some brands choose to block AI bots completely, but LLO usually recommends a more selective method-letting bots see authority-building content while blocking access to private datasets or paid-only assets. This fine-grained control helps shape a brand’s AI footprint so it is both positive and safe.
How LLO Improves AI Crawler Access and Visibility
How LLO Enables Efficient Content Discovery for AI Crawlers
In the AI era, efficiency means how easily a bot can map the links between your entities and topics. LLO supports this with a clear, logical URL structure and strong internal linking. In classic SEO, links pass “link juice.”
For LLMs, links help the model rebuild your site as a knowledge map. By removing redirect chains and fixing broken links, LLO stops AI crawlers from wasting “crawl budget” on dead paths and helps them revisit your full knowledge base more often.
LLO also highlights correct XML sitemaps with the <lastmod> tag. Freshness is a main ranking factor for AI retrieval systems. When a site uses LLO to update sitemaps automatically, it tells retrieval bots that content is current and reliable. This raises the chances of being chosen for time-sensitive questions, like new prices, updated rules, or breaking industry updates.
Does LLO Help with JavaScript Rendering Limitations?
Yes. LLO directly addresses the JavaScript gap. Since most AI crawlers treat JavaScript as plain text instead of running it, LLO moves the rendering work back to the server. By using Server-Side Rendering (SSR) or “Hydration” setups, LLO makes sure the crawler gets a fully filled-out HTML document. This lets AI engines index dynamic blocks-such as “Frequently Bought Together” modules or testimonial sliders-like any other text.
When full SSR is not possible, LLO can apply “Progressive Enhancement.” This method builds a strong, text-based HTML core that any bot can read, and then adds JavaScript features for human visitors. With this approach, the human user experience stays modern and interactive, while the AI crawler never hits a blank page or a constant “loading” spinner.
What Content Types Are Most Valuable for Generative Engines?
Generative engines favor content that supports reasoning. This covers clear guides, direct comparisons, and research backed by data. LLO supports these formats by presenting them in modular, easy-to-split blocks. When content is organized into clear H2/H3 headings, bullet lists, and Q&A sections, AI bots can lift short sections as ready-made answers in chat interfaces.
Original data-such as internal performance numbers or your own survey results-is especially valuable. LLMs reward “information gain”: content that truly adds new knowledge rather than just rephrasing what already exists online. LLO marks these data points with suitable Schema.org types (like Dataset or StatisticalVariable), making them highly attractive to AI models that need strong reference material.
How LLO Supports Answer Engines in Training and Generation
How Does LLO Structure Data for AI Training Models?
Training models consume billions of parameters to build their view of the world. LLO helps by adding rich Schema.org markup that clearly labels entities, authors, and relationships. With schemas such as Organization, Person, and Product, LLO helps AI engines tie your brand to known entities in their knowledge graphs. Keeping this consistent across your site, LinkedIn profiles, and sources like Wikidata supports the “trust” an LLM needs to recommend your brand.
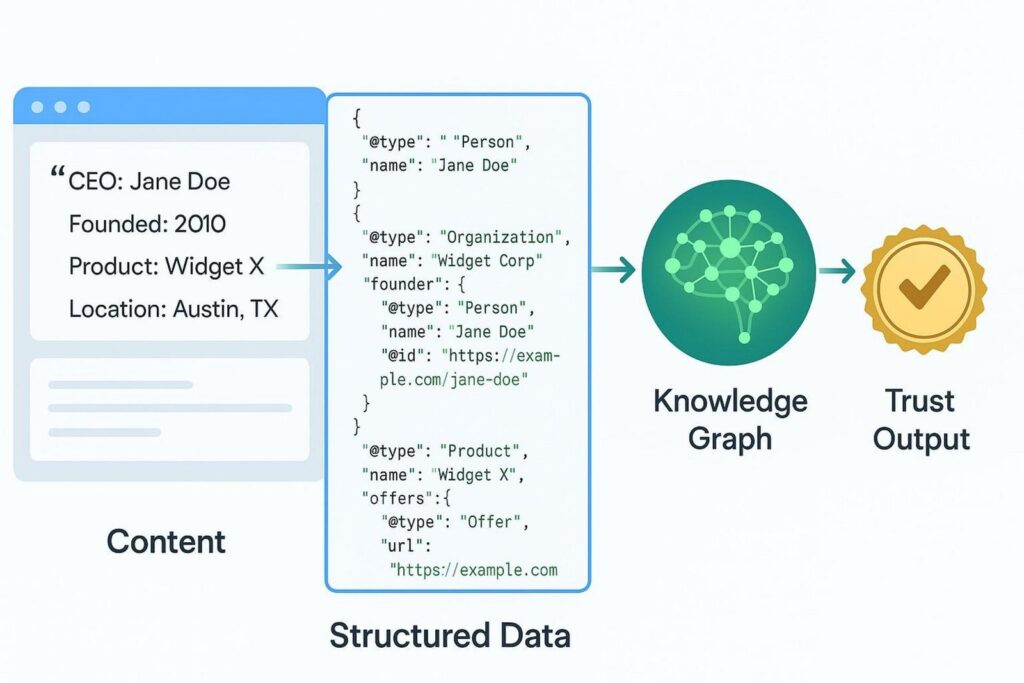
Beyond standard schema, LLO also focuses on grouping content by topic. By building topical “hubs,” LLO shows AI systems that your site is a focused library of expertise, not just random pages. This clear structure helps training pipelines treat your site as a strong authority for specific areas, supporting steady visibility in the model’s long-term knowledge.
Does LLO Help Ensure Accurate and Context-Rich Answers?
Answer engines work hard to avoid “hallucinations” by basing their output on solid data. LLO supports this by making facts easy to read and hard to misinterpret. With fact-dense paragraphs and clear on-page citations, LLO makes it simpler for an AI to check information. When an AI can confirm a fact on your site against other trusted sources (a process called “corroboration”), it is more likely to name you as a main source.
Context quality also improves with better metadata. LLO helps each page have unique, entity-rich titles and descriptions that match the “query fan-out” patterns used by AI engines. When an AI turns a short user question into a wider set of related sub-questions, LLO-optimized metadata helps map those sub-questions to the most relevant sections on your site.
Optimizing Websites with LLO for AI Crawlability and Answer Engine Performance
LLO Best Practices to Maximize Crawlability and Data Quality
To boost AI performance, LLO specialists follow an “HTML-First” approach. This means all mission-critical text appears in the server response. Using Semantic HTML5 tags (such as <article>, <section>, and <aside>) gives AI crawlers clear signals about which parts of a page are main content and which are side elements. This helps bots skip noisy areas like nav bars or ads and focus on the useful data.
Another key practice is adding “Freshness Cues.” These include visible “Last Updated” dates and short revision notes. For answer engines, a fact from 2026 is far more valuable than the same fact from 2024. LLO makes these timestamps readable both by humans and machines by adding them in JSON-LD schema, giving retrieval bots a clear signal that the content is recent.
How to Monitor AI Crawler Activity and Visibility Using LLO
Tracking AI activity means shifting from classic analytics tools to server log analysis. Many AI bots do not fire JavaScript-based trackers like Google Analytics, so you need to review raw server logs to spot agents such as GPTBot or PerplexityBot. LLO includes setting up real-time alerts for these user agents. A sharp rise in requests from a retrieval bot often comes just before your page starts appearing as a cited source in AI answers, giving you an early signal of AI visibility.
LLO also uses tracking tools that measure “zero-click” influence. By checking how often your brand or URLs show up in the “Sources” section of answer engines, you can judge how well your technical work is paying off. These insights then guide updates to your LLO plan, allowing you to invest more in the content formats and structures that AI engines find easiest to extract.
What Metrics Indicate Effective AI Crawlability?
The main success metric for AI crawlability is “Citation Rate”-how often your content is used as a source in generative answers. Technical proxy metrics matter too. These include the “HTML-to-Content Ratio” (to check that bots do not have to scroll through too much code to reach the main facts) and “Crawl Frequency” (how often bots like ChatGPT-User visit your site). A high crawl frequency often shows that the AI sees your site as fresh and reliable.
Another helpful metric is “Semantic Relevancy Score.” While it is hard to measure directly, you can estimate it by watching how your site performs on long, multi-part, conversational queries. If your site is cited for complex questions that need several steps to answer, it suggests that your LLO-based structure is helping the AI process and use your content. Tracking referral traffic from openai.com or perplexity.ai gives a clear, bottom-line view of how strong your AI discovery work is.
What Are the Risks and Limitations of LLO for AI Crawlers and Answer Engines?
LLO is powerful, but it is not a magic fix. A major risk is “Crawl Budget Bloat” on very large sites. If a site has millions of weak or unoptimized URLs, even strong AI crawlers may struggle to find and keep up with your most important updates. LLO needs to sit alongside strict content governance so bots mainly see high-value, authoritative pages.
If a site’s LLO plan pushes too hard on machine readability, it can also harm the human experience, lowering engagement and damaging classic SEO signals such as Core Web Vitals.
There is also the risk of “Revenue Leakage.” If your LLO strategy makes content too easy for AI to summarize, users might get everything they need in the AI answer and never visit your site, which can hurt ad income or lead generation. You need a careful balance: give enough data to earn citations and build brand authority, while keeping premium or interactive tools behind a click. On top of that, as AI models change, their crawling and parsing habits will shift, so LLO strategies must stay flexible and update often to match new bot behavior.
Key Takeaways for Enhancing AI Discovery with LLO
AI discovery is moving toward “agentic” search, where AI assistants do more than answer questions. They will carry out actions like “book the best-rated plumber in Chicago” or “buy the most durable running shoes under $100.” For a brand to be the one an AI chooses, its LLO work must go past simple text exposure. It needs “Action-Oriented” data formats, such as clear transactional schema and step-by-step process flows that let an AI agent guide a user smoothly through a conversion journey.
We are also seeing the growth of “Verified Source Ecosystems.” Soon, AI engines may favor content from brands that “register” their data feeds through APIs or verified llms.txt files. As AI moves from raw scraping toward structured data intake, LLO will increasingly involve managing direct data links with AI providers. By building a strong, machine-readable presence now, brands are preparing not just for current crawlers, but for the next wave of agent-based, multimodal web experiences.